Taking care of our clients' website's health
We take pride in making sure our clients’ websites are available around-the-clock, fully functional, and fast for their customers and constituents. We’re constantly looking for ways to improve the quality of service we deliver our clients and over the years we’ve only gotten better and better.
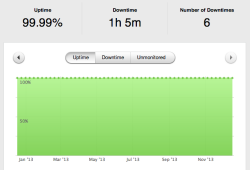
A screenshot from our Pingdom dashborad showing our server's uptime for 2013.
In the past year, our clients’ websites have seen 99.99% uptime. For reference, Google guarantees "critical projects will remain working 99.95 percent of the time, far better performance than in most corporate data centers". Maintaining “4 nines” of uptime is something we’re incredibly proud of. In absolute terms, we have had six downtimes of 11 minutes on average. More than half of the downtime occurred outside of business hours, most during early morning (2am-7am EDT) maintenance windows. In this post, I’ll cover some of the important techniques and tools we use to achieve this level of service.
Preventive Care
The best way to keep websites healthy and on-line is to prevent them from going down in the first place. From the ground up, we’ve deliberately chosen reliable, proven, industry-leading components to build our infrastructure (and open source software, everywhere possible).
Preventive Hardware Decisions
 All of our servers are dedicated and hosted in SoftLayer’s (now an IBM company) data centers. Their data centers are known to have exceptional networks, highly redundant infrastructure, and secure facilities.
All of our servers are dedicated and hosted in SoftLayer’s (now an IBM company) data centers. Their data centers are known to have exceptional networks, highly redundant infrastructure, and secure facilities.
Our dedicated servers are over-provisioned on CPU speed, RAM, and storage capacity to accommodate unexpected bursts and growth in activity to our clients’ sites. Hard drives are the most likely source of failure, so we always use redundant RAID configurations with hot-swappable enclosures to minimize the impact of hard drive failing.
Preventive Software Decisions
![]() Data Storage – Our content management systems, whether HiFi, WordPress, or Drupal, all use MySQL databases to store website content. Using MySQL’s InnoDB engine, all content changes are ACID transactions. For our clients this means ensuring website updates are stored reliably. In our uses, MySQL has never unexpectedly crashed or corrupted data. MySQL is proven and also used widely by Wikipedia, Twitter, and Facebook.
Data Storage – Our content management systems, whether HiFi, WordPress, or Drupal, all use MySQL databases to store website content. Using MySQL’s InnoDB engine, all content changes are ACID transactions. For our clients this means ensuring website updates are stored reliably. In our uses, MySQL has never unexpectedly crashed or corrupted data. MySQL is proven and also used widely by Wikipedia, Twitter, and Facebook.
 Web Serving – Requests for web pages are served by the nginx server software. It is extremely fast and reliable. At NMC, we’ve only seen it crash once across years and billions of requests served. Among the top 1,000 websites on the planet, nginx is the most trusted web server software [http://wpengine.com/2013/07/08/nginx-overtakes-apache-as-the-server-of-choice-for-the-top-1000-traff…]. Notable companies that also choose nginx include Netflix, LivingSocial, and Facebook.
Web Serving – Requests for web pages are served by the nginx server software. It is extremely fast and reliable. At NMC, we’ve only seen it crash once across years and billions of requests served. Among the top 1,000 websites on the planet, nginx is the most trusted web server software [http://wpengine.com/2013/07/08/nginx-overtakes-apache-as-the-server-of-choice-for-the-top-1000-traff…]. Notable companies that also choose nginx include Netflix, LivingSocial, and Facebook.
Content Caching – To accelerate how quickly we can deliver content to our clients’ website visitors, we use Varnish. The large majority of our client’s requests are served immediately from varnish cache which minimizes load times for site visitors. Varnish is another piece of software with a strong track record of reliability and used to accelerate top websites like the BBC, Zappos, Weather.com, and the Economist.com.
Offsite Backup – Every night we back up all of our websites offsite, to rsync.net. We maintain these nightly backups for 30 days to ensure that if a file or page gets deleted, whether accidentally or intentionally, we can quickly and easily recover it from any point in the last month. Other companies that trust backup data storage with rsync.net include Disney, Columbia University, and ESPN.
Monitoring Health – When a visitor browses any of our websites the pages visited get logged and aggregated using LogStash, ElasticSearch, and Kibana. These technologies feed data into our Quality of Service Dashboard. The dashboard highlights any performance or error issues in real time enabling us to proactively address issues before they spiral out of control.
Curative Care
![]() Even with a technology stack deliberately engineered to maximize reliability things can go wrong. Software can unexpectedly crash, hard drives can fail, and so on. In the event that our services go down, we’re the first to know and are working on it immediately. We use Pingdom to monitor the uptime of our services.
Even with a technology stack deliberately engineered to maximize reliability things can go wrong. Software can unexpectedly crash, hard drives can fail, and so on. In the event that our services go down, we’re the first to know and are working on it immediately. We use Pingdom to monitor the uptime of our services.
Within 60 seconds of an outage, Pingdom makes our phones and tablets blow-up with e-mail, texts, and Twitter Direct Messages. Immediately, someone on staff is logged in to the system and running through standard procedure diagnostics to determine what is wrong and how to bring service back on-line as quickly as possible.
For hardware issues, SoftLayer has dedicated support staff in the datacenter to quickly provide hands and eyes to diagnose and replace failing hardware components.
We’re Always Trying to Improve
We care a lot about keeping our customers’ websites online, fast, and error-free (and our own! we run our company and personal sites on the same infrastructure). Staying current with new technologies and best practices that allow us to better serve our clients is a core NMC value. We love doing it, too. We’re shooting for better than 99.99% uptime next year!
Related Posts


Leave the first comment