Introductory Regular Expression Tutorial
Regular expressions are a handy tool for developers to use. They're a concise, domain-specific language for pattern matching text. Regular expressions have many applications: input validation, data extraction, and advanced search and replace are a few good examples. In this introductory regular expression tutorial we'll take a high-level tour of primary concepts. We'll avoid details for now and revisit them in follow-up tutorials.
Use our free regex tester to follow along with this tutorial. It is web-based and written in JavaScript so no download is necessary. We'll be using JavaScript style syntax, which is closely related to its Perl regex inspiration. Most modern language regex implementations use a syntax like Perl/JavaScript's but the details for executing match and replace are language specific.
Simple Text Finding
If you've ever used 'Find' in a program like your web browser or text editor you've used a tool akin to the most basic regular expressions. For example, the regular expression /hifi/g will match the string 'hifi'. It will not match 'HiFi' or 'high-fidelity'.
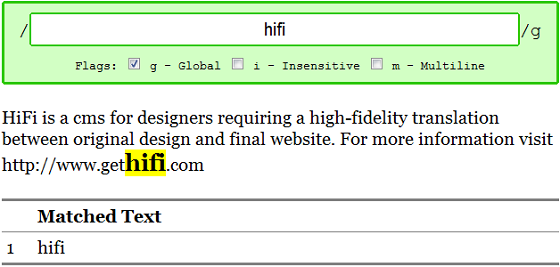
In order to match these three variations we can use regex choices, just like an OR.
This or That, Regex Choices
Choices are the 'OR' of regular expressions. The vertical bar character | denotes the "OR" between options. For example, /hifi|HiFi|high-fidelity/g, translates to 'hifi', or 'HiFi', or 'high-fidelity'.
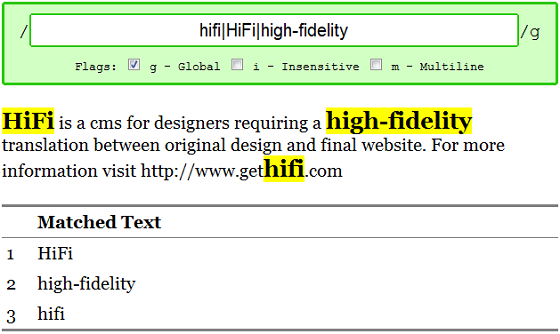
What if we wanted to choose between two options in the middle of a regex match string? For example, what if we wanted to match the words ending in an 'ood' or 'ould' sound in the classic tongue-twister 'How much wood would a woodchuck chuck'? We could repeat a lot of information or'ing each of the words like /wood|would|could/g or we could use matching groups and use a choice in the middle of the string.
Regex Matching Groups
Create matching groups by pairing parenthesis around a part of the regular expression. They allow you to 'pick out' important parts of a large match with sub-expressions. That sounds more complicated than it is. Let's look at a simple example: /(w|c)ould/g.

Notice how there's a special match on the first letter. We have essentially picked out the small part of the string we care about: the first letter of an 'ould' sounding word.
We can use a second group to match 'wood', too, with an or in the middle of the regex: /(w|c)(oul|oo)d/g
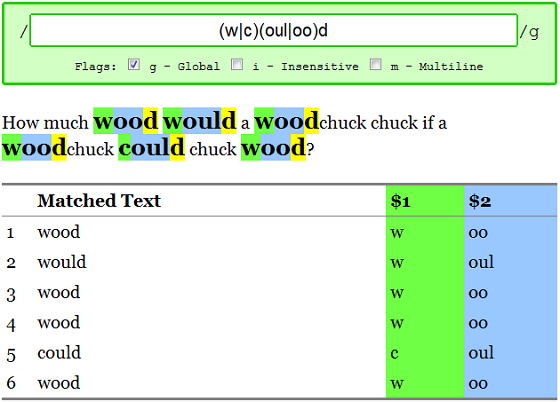
What else would this regex match that is not in this string? I'll leave this as an exercise to the reader.
How Many Times? Regex Quantifiers
If we care how many times a regex factor occurs, meaning characters, groups, and classes (up next), we can use a quantifier. Quantifiers come in two formats: ranges between curly braces and the special characters *, +, and ?.
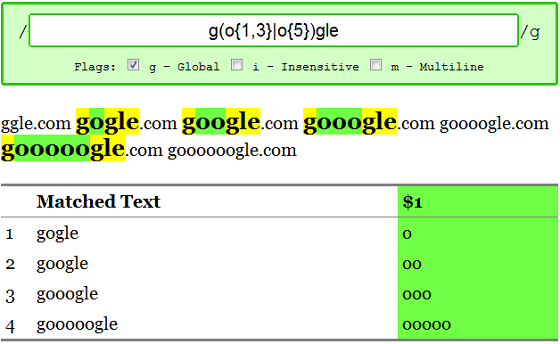
Let's talk about ranges first. Google owns a number of variations on the domain 'google.com' with varying numbers of 'o's. The following domains will all take you to Google: gogle.com, google.com, gooogle.com. We can capture any of these variations using a range quantifier: /go{1,3}gle/g.
It turns out, they also own the domain with 5 o's, but a squatter owns the domain with 4. So, we can put together the three big concepts we've learned so far: choices, groups, and quantifiers, to "match g followed by 1 to 3 o's or 5 o's followed by 'gle'" with this regex: /g(o{1,3}|o{5})gle/g.
Ranges in the form of {N,} that do not have a ceiling translate to "at least N times". We can use quantifiers on groups, too, so we can find all instances of the google domain with an even number of o's like this: /g(oo){1,}gle.com/g
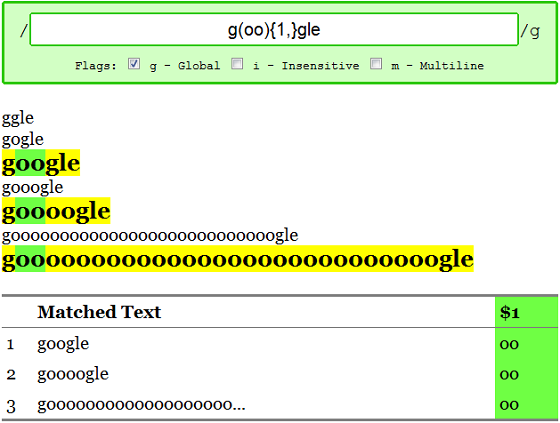
Now we're ready to start talking about the special quantifier characters. They're simple shortcuts for commonly used ranges:
*is{0,}- 0 or more matches?is{0,1}- 0 or 1 match+is{1,}- 1 or more matches
Thus, the previous example could have also been written as /g(oo)+gle.com/g
Regex Character Classes
We saw how we could match a 'w' or a 'c' using a group and a choice with (w|c). What if we wanted to match all vowels? /(a|e|i|o|u)/g. That's starting to get verbose!
There is a special construct in regular expressions called character classes, they are placed within square brackets []. For example, /[aeiou]/g and /(a|e|i|o|u)/g mean roughly the same thing. Ranges can be used, too, so [A-Z] is all uppercase English letters, [a-z] is all lowercase letters and [A-Za-z] all english letters. Finally, classes can be complemented with the ^ character to say "not any of these characters" so consonants could be described as the opposite of vowels: /[^aeiou]/g. (Note: Complements include all ASCII characters so [^aeiou] includes numbers, punctuation, etc.)
We can match words using a class of all English characters and a 1 or more quantifier, /[A-Za-z]+/g, such as:
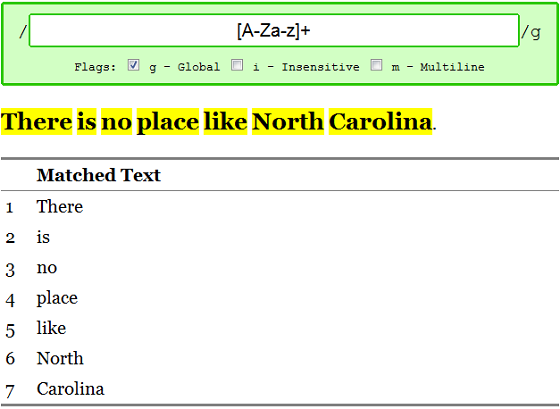
Pulling it All Together
As a last example let's put all the concepts we've covered in regular expressions together to pick out tags from an HTML file. HTML tags open like <div id="container"> and close like </h1>
Let's focus on finding opening tags, for now. They start with a less than sign and are followed by a letter, followed 0 or more other letters or numbers. We'll use a capturing group to pick out the important part: /<([A-Za-z][A-Za-z0-9]*)/g
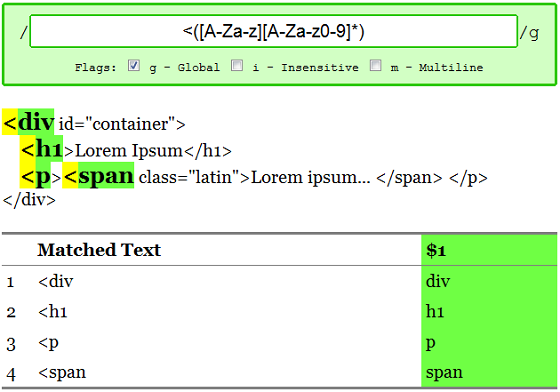
What if we wanted to pick out the attributes of a tag, too? We could match everything except the greater than character, using a complemented character class: ([^>]*)

As a final touch we can also match all closing tags, too. The difference between a closing tag and an opening tag is forward slash after the greater than sign like </ that. The slash can occur 0 or 1 times, 0 for opening, 1 for closing. The forward slash is a special regex character so it must be escaped with a backslash. We'll cover escaping special characters in a future post, for now just take my word that if you use \\/ it means simply a forward slash. So, this last little piece looks like (\\/?) and our product is /<(\\/?)([A-Za-z][A-Za-z0-9]*)/g
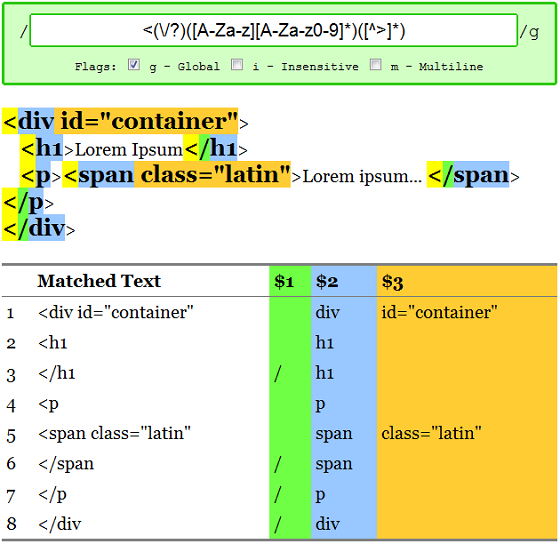
That's all for now, folks. We've seen how regular expressions can be used in the most basic sense as similar to your text editor's "find", covered choices which allow for ORs in our matching, used groups to pick out the important parts of a match, looked at sequences giving us the ability to specify how many times a match occurs, and finally poked around with character classes for concise lists of characters that match or do not match. Armed with just these tools you've got 80% of the power of regular expressions under your belt.
Unfortunately the other 20% of regular expression syntax is more detail oriented. These topics include special characters & escape codes, anchors, non-capturing groups, and lazy vs. greedy matching. We'll be covering these topics in future posts in this series. If you're eager to learn regular expressions you should subscribe to our development blog and continue playing around with our free regex tester.
Related Posts


Comments
kanchan
this is very usefull fo me.thanks
abhi
I having problem in regex..refer below link..
http://jsfiddle.net/abhishekbhalani/Wss89/
in that case I also want link as shown in result if link starts with ( "www" or "http://www" or "http://") then should be work on any case of URL. how I do it..
If I wrote "www.facebook.com/username.two" then it did not work.. How I do that.
Anoop Gupta
Awesome tutorial................helps a lot.Thank you very much
Diaa Kasem
A wonderful article, really basic but helpful and the tool also is awesome.
z.Yleo77
with those images, this question will be clear。。great
bill scabus
@Chuck - thank you.
I will read about lookahead/lookbehind.
Chuck
@bill scabus - First I would restate your spec as:
1. A number is a sequence of one or more digits.
2. A number sequence is a sequence of numbers separated by comma characters.
3. A comma character can only appear between two numbers.
4. A number cannot be repeated in a valid number sequence.
Basic Regular Expressions can handle requirements 1, 2 and 3 but cannot handle requirement 4. Some form of lookahead or lookbehind is required to satisfy that requirement. A parser is needed to satisfy that requirement.
bill scabus
great tutorial, but it didn't help me something I need.
I have to match the following pattern:
a sequence of digits followed by a comma, but the sequence ends with a digit, and the digits can't be repeated.
possible values:
1,2,5,6,20,40,65
10,25,300,1000,6666
non-valid:
1,2,1
1,1,1
someone has any idea on how can I use group to achieve this?
Vipul Limbachiya
This is an amazing article, it helped me a lot to understand regExp.
Thanks for sharing!
Regards,
Vipul
Leave a comment